更聰明的秘密武器,做出專屬的企業 AI 知識庫")
在當今快速變化的數位時代,企業面臨著前所未有的數據處理需求。為了應對這些挑戰,企業紛紛建立自己的大型語言模型(LLM),利用大量數據進行訓練,讓模型能夠理解並生成自然語言,從而實現人機協作,優化業務流程並提升客戶體驗。
然而,資料清理在這個過程中顯得至關重要。若企業未能妥善管理和清洗數據,將會陷入“劣質數據,誤導結果”(Garbage in, Garbage out, GIGO)的困境。也就是說,用不準確或無效的數據訓練模型,最終的預測和決策結果同樣會是錯誤的。
即便擁有乾淨的數據,在運用 LLM 時仍會遇到一些限制。首先,LLM 的知識僅限於訓練數據範圍,對於特定領域的專業知識和最新資訊可能不夠全面。當模型缺乏相關上下文或使用過時的數據時,可能會產生“幻覺”現象,即生成不準確或錯誤的回應。為了克服這些挑戰,開發者越來越關注生成式 AI 和檢索增強生成(Retrieval-Augmented Generation, RAG)技術。
RAG (Retrieval-Augmented Generation) 是什麼?
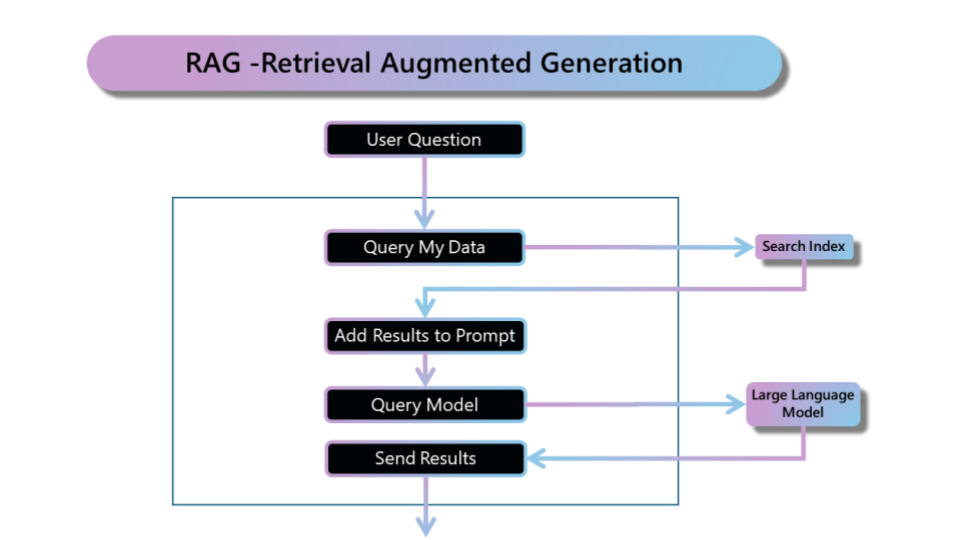
檢索增強生成(RAG,Retrieval-Augmented Generation)是一種對大型語言模型輸出優化的流程,將 LLM 與來自其他資料源的後端資料檢索相結合的架構模式。這種方法透過先檢索企業內部或外部的相關資料,然後結合 LLM 的生成能力,提供更加準確和具體的回應。由自然語言處理科學家 Patrick Lewis 等於 2020 年提出。最原始 RAG 的流程工作其原理主要分為兩大階段:檢索和生成技術,其核心概念是在生成回應前,從外部資料庫中檢索相關資訊,再與原本要詢問 LLM 的問題結合,一併提供給 LLM,使其能夠依據檢索的資料生成更準確、具體的回應。
目前 RAG 使用的不只是傳統的資料庫,也有向量資料庫(vector database)。在資料處理的過程中,將可以提供給大型語言模型做參考的文字、圖片、聲音、影片等非結構化資料切分成小區塊,並透過嵌入(Embedding)技術將資料轉換為向量,存放於向量資料庫中,當大型語言模型回答問題時,可以找出與提示詞最相關的資料,作為 LLM 回應的參考。
IBM 的語言技術總監 Luis Lastras 用 open book 比喻 RAG 與 Fine-tuning 的差異:「使用RAG系統時,你要求模型從資料庫中檢索內容,而不僅依靠 Fine-tuning 的記憶回答問題。」
RAG (Retrieval-Augmented Generation) 需要做哪些資料處理?
RAG 結合了搜尋系統和生成語言模型的優勢,但能夠充分發揮優勢的前提是搜尋系統要能爲大型語言模型提供精準的相關結果,提供不準確或錯誤的搜尋結果反而會使大型語言模型回答出更離譜的答案。優秀的搜尋系統往往需要精細且可靠的資料前處理,以目前搜尋系統主流使用的向量資料庫來說,資料前處理有以下三大步驟:
- 檔案文字提取
文字提取包含了各種來源、檔案格式(word, pdf, 圖片, 影片, 網頁等等)的資料,且不僅僅是擷取文件中的文字,如何保留文件中有意義的表格、圖片與流程圖等等的非文字資訊才是關鍵。 - 文字資訊切檔
大型語言模型都有輸入文字的上限,在過去,為了避免無法提供完整文件內容給大型語言模型的問題我們會將提取出來的檔案文字做切檔。隨著語言模型的更新,可以一次性輸入的文字也大幅提升,例如 Gemini 1.5 Pro 可以一次接受 128k token 的輸入(粗略估計大概 5 集哈利波特的內容),但我們很難控制大型語言模型在長文本中關注的重點(就像是正在開書考試的學生,如果抓錯課本的重點仍然會回答不好),且每次呼叫大型語言都提供超長提示詞會導致費用高昂,因此文字資訊切檔仍有其必要性。 - 文字轉向量
文字轉向量是將資料儲存進向量資料庫前的最後一步,Google text embedding 可以依照不同應用任務(文本搜尋、分類、分群等等),最佳化文字轉向量的結果,完整保留文字中的語意資訊,且支援多國語系。
總結來說,搜尋系統的資料前處理環環相扣,每一個步驟處理不好都會影響下一步驟的產出,最終導致 RAG 的效果大打折扣。
Vertex AI Agent Builder – 輕鬆建立企業級 RAG 系統的秘密武器
如前言所述,大型語言模型(LLM)基於廣泛的公開數據進行訓練。然而,僅依賴這些數據的模式和經驗,LLM 缺乏真正的理解能力,這導致其在處理企業內部數據時常出現領域知識不足、事實性問題及幻覺現象。此外,如果模型無法不斷學習,便無法跟上知識的更新速度。
企業可以使用 RAG 技術,將內部的產品數據、技術文檔或客戶服務記錄整合進來。在 RAG 技術中,關鍵在於如何確保語意空間的精確性,以及如何使擷取的資訊與 LLM 生成的內容協調一致。這包括比對查詢和文件的語意空間,以確保擷取器能夠提供最相關和最有用的資訊,從而幫助 LLM 生成自然流暢的文字。
Vertex AI 的 Agent Builder 能夠大幅簡化許多複雜的步驟,例如資料解析(Parsing)、嵌入(Embedding)和索引(Indexing)等。這讓使用者只需專注於管理自己的資料,準備好企業知識,其餘的編碼工作由 Agent Builder 來完成。不論所處的產業,RAG 技術都具有廣泛的適用性。
透過使用 Vertex AI Agent Builder,企業能夠輕鬆建立並維護一個強大的 RAG 系統,確保其 AI 應用在處理內部數據時具備高效性和準確性,從而提升整體競爭力。
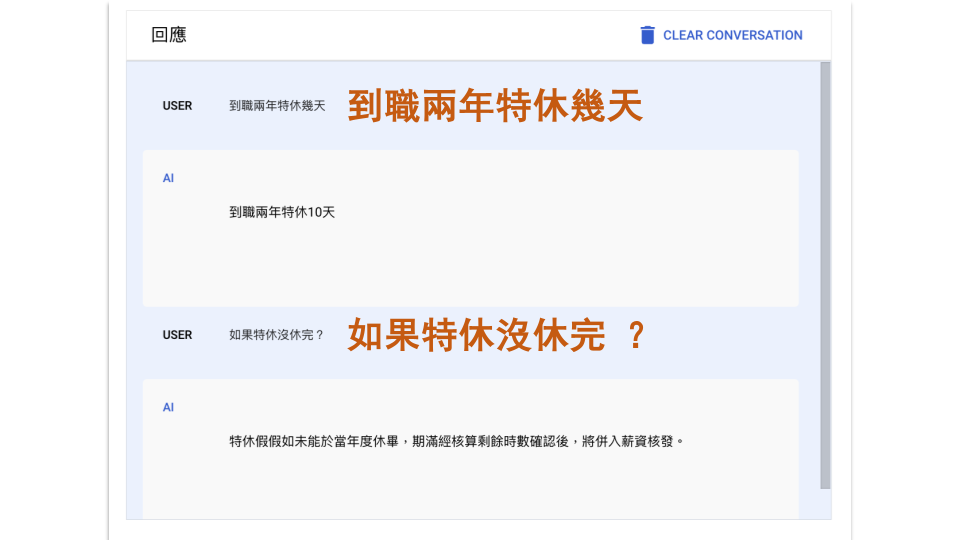
cacaFly 雲端智能中心專注於協助企業建立核心知識庫。企業在使用知識庫時,常常面臨用戶提問不易理解,導致無法準確找到相應回覆的資料。針對這一挑戰,cacaFly 提出了一個解決方案——透過 AI 先行解析公司內部資料,將用戶問題優化成更易於查詢的形式。
這一技術被 cacaFly 稱為 Enhancer 技術,大大提升了生成式 AI 在 RAG(檢索增強生成)方面的效果,成功使正確率提升至 60%。
AI 轉型的關鍵:不只是工程師,第一線人員同樣重要
在當前快速變遷的商業環境中,AI 技術的應用變得越來越重要。尤其是 RAG(檢索增強生成)技術,能顯著提升大型語言模型(LLM)的效能。這項技術不僅能減少模型的幻覺現象,還能增強回應的事實性和專業性,對於需要處理大量專業數據並提供個性化服務的企業尤為重要。RAG 技術彌補了 LLM 的不足,更好地滿足企業的特定需求,使企業在 AI 時代中保持競爭優勢。
然而,當企業希望導入 AI 或進行模型訓練時,資料的品質是影響成效的關鍵因素之一。我們經常與各產業領域的需求方討論資料欄位的意義和代表的內容,因為第一線人員最了解這些資料。如果資料定義不夠清晰,工程師訓練 AI 的效果往往不理想,這並非完全是工程師的責任。許多人往往忽略這一點,實際上,資料的品質和定義在其中扮演了至關重要的角色。
這意味著,AI 轉型不僅僅是工程師的責任,第一線人員同樣肩負重任。他們對資料的深入理解和精確定義,直接影響到 AI 技術的應用效果。因此,在推動 AI 轉型的過程中,我們需要加強第一線人員與工程師之間的合作,確保資料的質量和準確性,才能真正發揮 AI 的潛力,為企業帶來競爭優勢。
參考資料
https://research.ibm.com/blog/retrieval-augmented-generation-RAG